数据挖掘(Data mining,简称DM)从狭义上是指从数据库中提取知识。具体的说是在数据库中,对数据进行一定的处理,从而获得其中隐含的、事先未知的而又可能极为有用的信息。这些信息通常是以知识、规则或约束等形式来表现。在其他文献中有许多类似的提法,例如:数据分析,知识获取,知识萃取,数据构成等。数据挖掘方法在数据库系统和人工智能领域是一个新方向。
数据挖掘一般分为以下几个主要步骤:
1.数据收集
大量全面丰富的数据是数据挖掘的前提,没有数据,数据挖掘也就无从作起。因此,数据收集是数据挖掘的首要步骤。数据可以来自于现有事务处理系统,也可以从数据仓库中得到。
2.数据整理
数据整理是数据挖掘的必要环节。由数据收集阶段得到的数据可能有一定的“污染”,表现在数据可能存在自身的不一致性,或者有缺失数据的存在等,因此数据的整理是必须的。同时,通过数据整理,可以对数据做简单的泛化处理,从而在原始数据的基础之上得到更为丰富的数据信息,进而便于下一步数据挖掘的顺利进行。
3.数据挖掘
利用各种数据挖掘方法对数据进行分析。
4.数据挖掘结果的评估
数据挖掘的结果有些具有实际意义,而另一些没有实际意义,或是与实际情况相违背,这就需要进行评估。评估可以根据用户多年的经验,也可以直接用实际数据来验证模型的正确性,进而调整挖掘模型,不断重复进行数据挖掘。
5.分析决策
数据挖掘的最终目的是辅助决策。决策者可以根据数据挖掘的结果,结合实际情况,调整竞争策略等。
数据挖掘技术的目标是从大量数据中,发现隐藏于其后的规律或数据间的关系,从而服务于决策。 NLPIR文本搜索与挖掘系统平台针对互联网内容处理的需要,融合了自然语言理解、网络搜索和文本挖掘的技术,提供了用于技术二次开发的基础工具集。系统平台包括:全文精准检索、新词发现、分词标注、统计分析、文本聚类、分类过滤、正负面分析、自动摘要等十多个中间件组成,各个中间件API可以无缝地融合到客户的各类复杂应用系统之中。
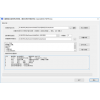
NLPIR是一套专门针对原始文本集进行处理和加工的软件,提供了中间件处理效果的可视化展示,也可以作为小规模数据的处理加工工具。用户可以使用该软件对自己的数据进行处理。
数据挖掘是在数据库中对数据进行一定的处理,从而获得其中隐含、事先未知的而又可能极为有用的信息。这些信息通常是以知识、规则或约束等形式来表现。这些知识可以用于知识管理、问题求解、制定决策、过程控制和其他领域。